数据库复习
题型
单选:10 个 × 2 分
填空:10 个 × 1 分
综合应用题:3 个,每个 10-30 分(考察 2-6 章知识点,重点为关系代数和 sql 语句)
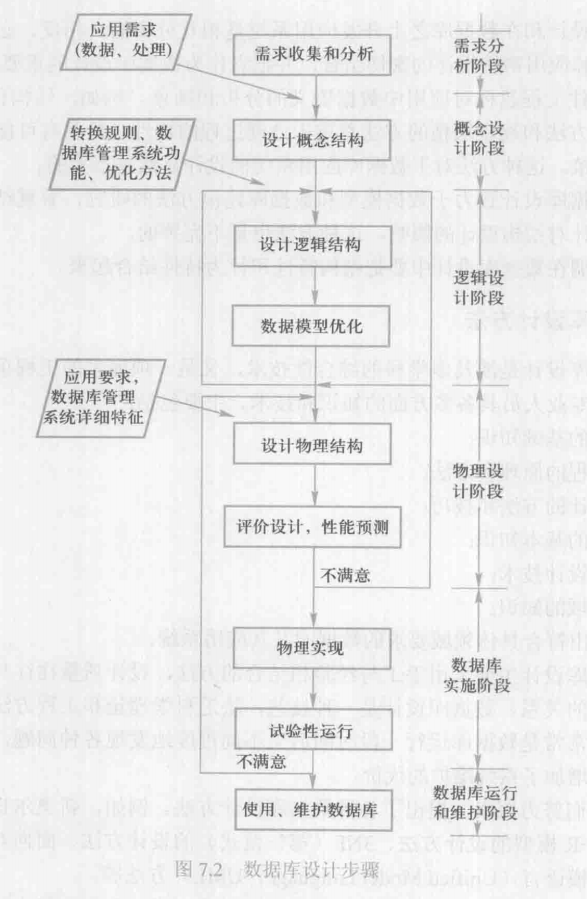
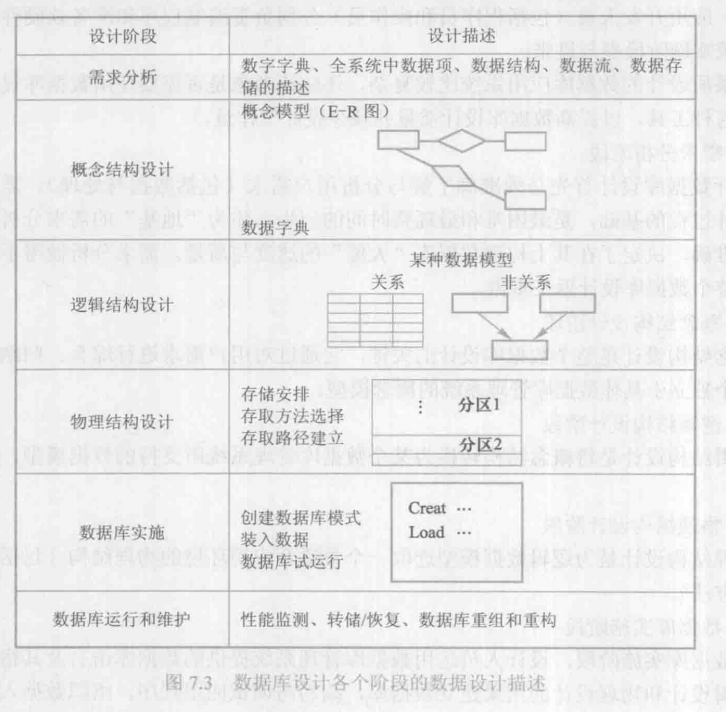
第一章 数据库系统概述
- 数据库的 4 个基本概念
- 数据
- 数据库
- 数据库系统 = 数据库 + 数据库管理系统 + 应用程序 + 数据库管理员
- 数据库管理系统:本质是软件
第二章 关系数据库
关系数据结构及形式化定义
- 域:概念上等同于集合
- 笛卡尔积:几个集合取乘积(类似于乘法分配律)所得的集合,不能有重复元素
- 基数:一个域中的不同元素的个数叫做域的基数
- 关系:若干个域的笛卡尔积的子集叫做域上的关系,写为 $R(D_1,D_2,\ldots ,D_n)$,其中 n 叫做关系的目或者度
- 候选码:关系中某一属性组能唯一标识一个元组,而其子集不能,这个属性组叫做候选码。(不能有重复的取值)
- 主码:一个关系有多个候选码时,选定其中一个为主码。候选码的诸属性叫主属性
- 关系的三种类型:基本关系(基本表),查询表,视图表
- 表中不能有小表
- 关系模式:$R(U,D,DOM)$
关系操作
- 基本的关系操作:
- 查询(前五种为五种基本操作)
- 选择
- 投影
- 并
- 差
- 笛卡尔积
- 连接
- 除
- 交
- 插入、删除、修改
- 查询(前五种为五种基本操作)
关系的完整性
- 实体完整性:主属性不能取空值
- 参照完整性:
- F 是关系 R 的属性但不是码,K 是关系 S 的主码,如果 F 和 K 相对应,则 F 是关系 R 的外码,称 R 是参照关系,S 是被参照关系。R、S 可以是同一关系。
- F 是关系 R 的外码,则 F 的各个取值或者取空值,或者等于 S 中对应的值
- 用户定义的完整性
关系代数
用对关系的运算表达查询
传统的集合运算
- 并 $R \cup S$,两集合取并集
- 差 $R - S$,属于 R 但不属于 S
- 交 $R \cap S$,两集合取交集
- 笛卡尔积 $R \times S$
专门的关系运算
选择(限制):在关系R中选择满足给定条件的诸元组,$\sigma F(R)$(例如,$\sigma {Sdept=’IS’}(student)$),其中F表示选择条件。是从行的角度进行的运算。
投影:从关系R中选择出若干属性列组成新的关系,$\piA(R)$(例如,$\pi{Sname}(student)$),其中 A 是 R 的属性列,结果应取消相同行。是从列的角度进行运算。
连接:从两个关系的笛卡尔积里选择满足关系的元组,$R \underset{A\theta B}\Join S$,其中 $\theta$ 为比较运算符。
- 等值连接:当 $\theta$ 为 ”$=$“ 时
- 自然连接:特殊的等值连接,进行比较的分量必须是同名的属性组,并在结果中取消重复列。同时从行和列的角度进行运算。
- 外连接
- 悬浮元组:自然连接运算中被舍弃的元组
- 外连接:把悬浮元组也保存在结果关系中,在其他属性填 $NULL$,$R\ ⟗\ S$
- 左外连接:只保留左边关系 R 的悬浮元组,$R\ ⟕\ S$
- 右外连接:只保留左边关系 S 的悬浮元组,$R\ ⟖\ S$
- 等值连接:当 $\theta$ 为 ”$=$“ 时
除:$R\div S=T$,$T$ 包含在 R 但不在 S 中的属性及其值。同时从行和列的角度进行运算。
类似于在两关系的共同属性上一一对照,找到左边关系中含右边关系的所有非共同属性的非共同属性,即为运算结果。
第三章 关系数据库标准语言 SQL
概述
- SQL 的特点
- 综合统一
- SQL 集数据定义语言、数据操纵语言、数据控制语言、数据查询语言的功能于一体
- 高度非过程化
- 面向集合的操作方式
- 提供多种使用方式
- 语言简洁,易学易用
- 综合统一
数据定义
模式
定义
create schema <模式名> authorization <用户名>

删除
drop schema <模式名><cascade(级联)|restrict(限制)>
级联和限制必选其一,级联表示把该模式的数据库对象全部删除;限制表示如果已经该模式中如果已经定义了下属的数据库对象,就拒绝该语句的执行。

常用完整性约束

基本表

定义表
create table <表名>(
<列名><数据类型> [列级完整约束条件]
[,<表级完整约束条件>]);删除表
drop table <表名> [restrict|cascade];
- restrict:删除表有限制条件。欲删除的基本表不能被其他表的约束所引用,如果存在依赖该表的对象,则此表不能被删除。 默认是 restrict。
- cascade:删除表没有限制条件。在删除基本表的同时,相关的依赖对象一起删除

模式与表
表中给出模式名

创建模式语句中同时创建表

修改表
alter table <表名>
[add <新列名> <数据类型> [完整性约束]]
[drop <完整性约束名>]
[alter column <列名> type <数据类];
表级完整性约束条件定义

索引
分类
- 普通索引(normal Index):索引表的 Search-key 项中的每一索引值对应全部取该值的基本表中的记录。普通索引通过索引表的指针项指向一个单链表来实现,该链表的每个结点的数据项指向一条物理记录。
- 单一索引(unique Index):每一个索引值只对应唯一的数据记录。当建立单一索引后,索引项不可以再插入已有值,但可以插入多个空值,这等同于在建表时对索引列增加一个 UNIQUE 约束;同样,当建立单一索引时,如果待索引项存在相同值则不能建立。
- 聚簇索引(cluster Index):索引项顺序与表中数据记录的物理顺序一致。即基本表是按照索引表的 Search-key 项的排列次序组织存储的,因此,一个基本表只能建立一个聚簇索引。
建立索引
create [unique] | [cluster] index <索引名>
on <表名>(<列名>[<次序>][,<列名>[<次序>] ]…) ;用表名指定要建索引的基本表名字
索引可以建立在该表的一列或多列上,各列名之间用逗号分隔
用次序指定索引值的排列次序,升序:ASC,降序:DESC;缺省值:ASC
unique 表明此索引的每一个索引值对应唯一的数据记录
cluster 表示要建立的索引是聚簇索引

删除索引
alter table <表名> drop index <索引名>;

数据查询
单表查询
select 语句
SELECT [ALL | DISTINCT] <目标列表达式> [,<目标列表达式>] …
FROM <表名或视图名>[, <表名或视图名> ] …
[ WHERE <条件表达式> ]
[ GROUP BY <列名1> [ HAVING <条件表达式> ] ]
[ ORDER BY <列名2> [ ASC | DESC ] ] ;- select 子句:指定要显示的属性列
- from 子句:指定查询对象(基本表或视图)
- where 子句:指定查询条件
- group by 子句:对查询结果按指定列的值分组,该属性列值相等的元组为一个组。通常会在每组中使用集函数;having 短语:筛选出只有满足指定条件的组
- order by 子句:对查询结果按指定列值升序或降序排序
选择表中的若干列($\pi$)

查询指定列
查询全部列
select *
from <table>;查询经过计算的值

选择表中的若干元组
消除取值重复的行:distinct

查询满足条件的元组:where($\sigma$)
比较

确定范围:between and,not between and

确定集合:in,not in

字符匹配:like,not like
- %:任意长度字符串
- _:任意单个字符

涉及空值的查询:is nullI,is not null

多重条件(逻辑运算):and,or,not

order by 语句
- 可以按一个或多个属性列排序
- 升序:ASC
- 降序:DESC
- 默认为升序
- 当排序列含空值时:将空值作为最大值来理解

- 可以按一个或多个属性列排序
聚集函数(count,sum,avg,max,min:只能用于 SELECT 语句和 GROUP BY
计数
COUNT ([DISTINCT|ALL] *) COUNT ([DISTINCT|ALL] <列名>)
计算总和
SUM ([DISTINCT|ALL] <列名>)
计算平均值
AVG ([DISTINCT|ALL] <列名>)
求最大值
MAX ([DISTINCT|ALL] <列名>)
求最小值
MIN ([DISTINCT|ALL] <列名>)
GROUP BY 语句

连接查询
等值与非等值连接查询

- 自然连接:等值连接中,去掉重复的属性列为自然连接
自身连接

外连接
- 左外连接列出左边关系所有元组
- 右外连接列出右边关系所有元组

多表连接

嵌套查询
查询块:一个 select-from-where 语句称为一个查询块
带有 IN 谓词的子查询
- 不相关子查询:子查询的查询条件不依赖于父查询(可以用自身连接)
- 相关子查询:子查询的查询条件依赖于父查询


带有比较运算符的子查询(比较运算符)

带有 ANY(SOME)或 ALL 谓词的子查询(效率低于聚集函数)

带有 EXISTS 谓词的子查询,不返回任何值,只产生逻辑真,假


集合查询
- 并 union:将多个查询结果合并,自动去掉重复元组
- 交 intersect
- 差 except

基于派生表的查询
数据更新
插入数据
插入元组 INSERT INTO VALUES
INSERT INTO <表名> [(<属性列1>[,<属性列2 >…)]
VALUES (<常量1> [,<常量2>] … ) ;- INTO 子句
- 指定要插入数据的表名及属性列
- 属性列的顺序可与表定义中的顺序不一致
- 没有指定属性列:表示要插入的是一条完整的元组,且属性列属性与表定义中的顺序一致
- 指定部分属性列:插入的元组在其余属性列上取空值
- VALUES 子句:提供的值的个数和值的类型必须与 INTO 子句匹配

- INTO 子句
插入子查询结果 INSERT INTO 子查询
INSERT INTO <表名> [(<属性列1> [,<属性列2>… )]
子查询;- INTO 子句,与插入单条元组类似
- 子查询,SELECT 子句目标列属性的个数和类型必须与 INTO 子句匹配。
修改数据 UPDATE SET
语法
UPDATE <表名>
SET <列名>=<表达式>[, <列名>=<表达式>]…
[WHERE <条件>];SET 子句:指定修改方式,要修改的列和修改后取值
WHERE 子句
- 指定要修改的元组
- 缺省表示要修改表中的所有元组
修改某一个元组的值

修改多个元组的值

带子查询的修改语句

删除数据(DELETE 只删除表的数据,不删除表的定义)
语法
DELETE FROM <表名>
[WHERE <条件>] ;- WHERE 子句
- 指定要删除的元组
- 缺省表示要修改表中的所有元组
- WHERE 子句
删除某一个元组的值

删除多个元组的值

带子查询的删除语句

空值的处理
空值的判断:is null,is not null

空值的约束条件
- 有 NOT NULL 约束条件的不能取空值
- 加了 UNIQUE 限制的属性不能取空值
- 码属性不能取空值
空值的运算
- 算术运算:空值与另一个值(包括另一个空值)的算术运算的结果为空值
- 比较运算:空值与另一个值(包括另一个空值)的比较运算的结果为 UNKNOWN
- 逻辑运算:有 UNKNOWN 后,传统二值(TRUE,FALSE)逻辑就扩展成了三值逻辑
视图
是一个虚表
对应三级模式的外模式
定义视图
建立视图
CREATE VIEW <视图名> [(<列名> [,<列名>]…)]
AS <子查询>
[WITH CHECK OPTION];- CREATE VIEW 子句中的列名可以省略,此时视图的属性由子查询中 SELECT 目标列中的诸字段组成。但在下列情况下明确指定视图的所有列名:
- 某个目标列是集函数或列表达式
- 多表连接时选出了几个同名列作为视图的字段
- 需要在视图中为某个列启用新的更合适的名字
- 子查询中的属性列不允许定义别名,不允许含有 ORDER BY 子句和 DISTINCT 短语。
- WITH CHECK OPTION 表示对视图进行更新操作的数据必须满足视图定义的谓词条件(子查询的条件表达式)。


- CREATE VIEW 子句中的列名可以省略,此时视图的属性由子查询中 SELECT 目标列中的诸字段组成。但在下列情况下明确指定视图的所有列名:
删除视图
DROP VIEW <视图名> [CASCADE] ;
查询视图
和基本表一样
- 如果该视图导出了其他视图,则使用CASCADE级联删除,或者先显式删除导出的视图,再删除该视图;
- 删除基表时,由该基表导出的所有视图定义都必须显式删除。
DBMS 实现视图查询的方法
实体化视图

视图消解法

更新视图
- 插入 INSERT
- 删除 DELETE
- 修改 UPDATE

- 视图的作用
- 简化用户的操作
- 使用户能以多种角度看待同一数据
- 对重构数据库提供了一定程度的逻辑独立性
- 对机密数据提供安全保护
第四章 数据库安全性
定义
是指保护数据库以防止不合法使用所造成的数据泄露,更改和破坏
不安全因素
- 非授权用户对数据库的恶意存取和破坏
- 数据库中重要或敏感数据被泄露
- 安全环境的脆弱性
数据库的安全性控制
用户身份鉴别
- 每个用户由用户名 username 和用户标识号 UID 组成
- 常用的用户身份鉴别方法
- 静态口令鉴别:用户名和密码
- 动态口令鉴别:短信验证码
- 生物特征识别:指纹,声纹,虹膜
- 智能卡鉴别
存取控制
存取控制机制主要包括定义用户权限和合法权限检查两部分
自主存取控制 DAC
用户权限由两个要素组成:数据库对象和操作类型
授权:授予和收回
授权
grant <权限> on <对象类型> <对象名>
to <用户>收回
revoke <权限 >on <对象类型> <对象名>
from <用户>with grant option 子句使得获得某种权限的用户把权限再授予其他用户
数据库角色
定义:是被命名的一组与数据库操作相关的权限,是权限的集合
使用
角色的创建:
create role <角色名>
给角色授权:
grant <权限> on <对象类型><对象名>to<角色名>
将一个角色授予其他的角色或用户
grant <角色1>,...to <角色3>[,<用户1>]
[with admin option]角色权限的收回
revoke <权限> on <对象类型> <对象名>
from <角色>
自主存取控制,仅仅通过对数据的存取权限来进行安全控制,而数据本身并无安全性标记
强制存取控制 MAC
- 全部实体分为主体和客体
- 主体是系统中活动实体,实际用户和各进程
- 客体是系统中被动实体,包括文件、基本表、索引、视图等
- 对于主体和客体,DBMS 为每个实例(值)指派一个敏感度标记
- 敏感度标记被分为若干级别:绝密、机密、可信、公开
- 主体的敏感度标记称为许可证级别,客体的敏感度级别称为密级
- 主体对任何客体的存取需遵循的规则
- 仅当主体的许可证级别大于或等于客体的密级,该主体才能读取相应的客体
- 仅当主体的许可证级别小于或等于客体的密级,该主体才能写相应的客体
- 全部实体分为主体和客体
视图控制:为不同用户定义不同的视图,把数据库对象限制在一定范围内
数据加密存储和加密传输
第五章 数据库完整性
定义
是指数据的正确性和相容性
实体完整性
create table student( |
将属性组定义为主码只能在表级
参照完整性
create table student( |
用户定义的完整性
属性上的约束条件
列值非空
create table student
(sno char(9) not null,/*属性不允许取空*/
sname ... not null,
cno... not null,
primary key (sno, cno)
);列值唯一
create table student
(sno char(9) not null,
sname ... unique not null,/*列值唯一且不取空*/
cno... not null,
primary key (sno, cno)
);检查列值是否满足一个条件表达式(check 表达式)
create table student
(sno char(9) not null,
sname ... not null,
ssex char(2) check (ssex in('男','女')),/*性别只允许取男女*/
...
primary key (sno, cno)
);
元组上的约束条件
create table student
(sno char(9) not null,
sname ... not null,
ssex char(2),
...
primary key (sno, cno)
check (ssex='女' or sname not like 'Ms.%'),/*性别女的不允许叫 Ms.%*/
);
完整性约束命名子句
在创建表时,可以增加、删除一个完整性约束条件
constraint <完整性约束条件名> <完整性约束条件>
修改表中的完整性约束限制
ALTER TABLE表名
Drop Constraint<完整性约束条件>
ALTER TABLE表名
ADD Constraint<完整性约束条件><CHECK短语>
第六章 关系数据理论
关系模式的问题
- 数据冗余
- 更新异常
- 插入异常
- 删除异常
函数依赖
x 函数确定 y,y 函数依赖于 x,写为 $x\to y$
- $x\to y$,$y\subsetneq x$,非平凡函数依赖
- $x\to y$,$y\subseteq x$,平凡函数依赖
- $x\to y$,$y\to x$,记作$x\leftarrow \to y$
- y 不函数依赖于x,记作 $x\nrightarrow y$
- 完全函数依赖:$x\to y$,且对 x 的子集 x’,都有$x’\nrightarrow y$,则 y 对 x 完全函数依赖,记作 $x \stackrel{F}\to y$
- 不完全函数依赖:$x\to y$,但y 对 x 不完全函数依赖,记作 $x \stackrel{P}\to y$
- 传递依赖
范式

- 1NF:表不可再分
- 2NF:任意候选码都是非主属性的完全函数依赖
- 3NF :不存在 ”关键字->==非关键字->非关键字==“
- BCNF:即每个依赖左边必包含码,即不存在”==关键字x->关键字y==->非关键字“